Künstliche Intelligenz - Prof. Dr. Norbert
Pohlmann
Künstliche Intelligenz
Inhaltsverzeichnis
Was ist Künstliche Intelligenz?
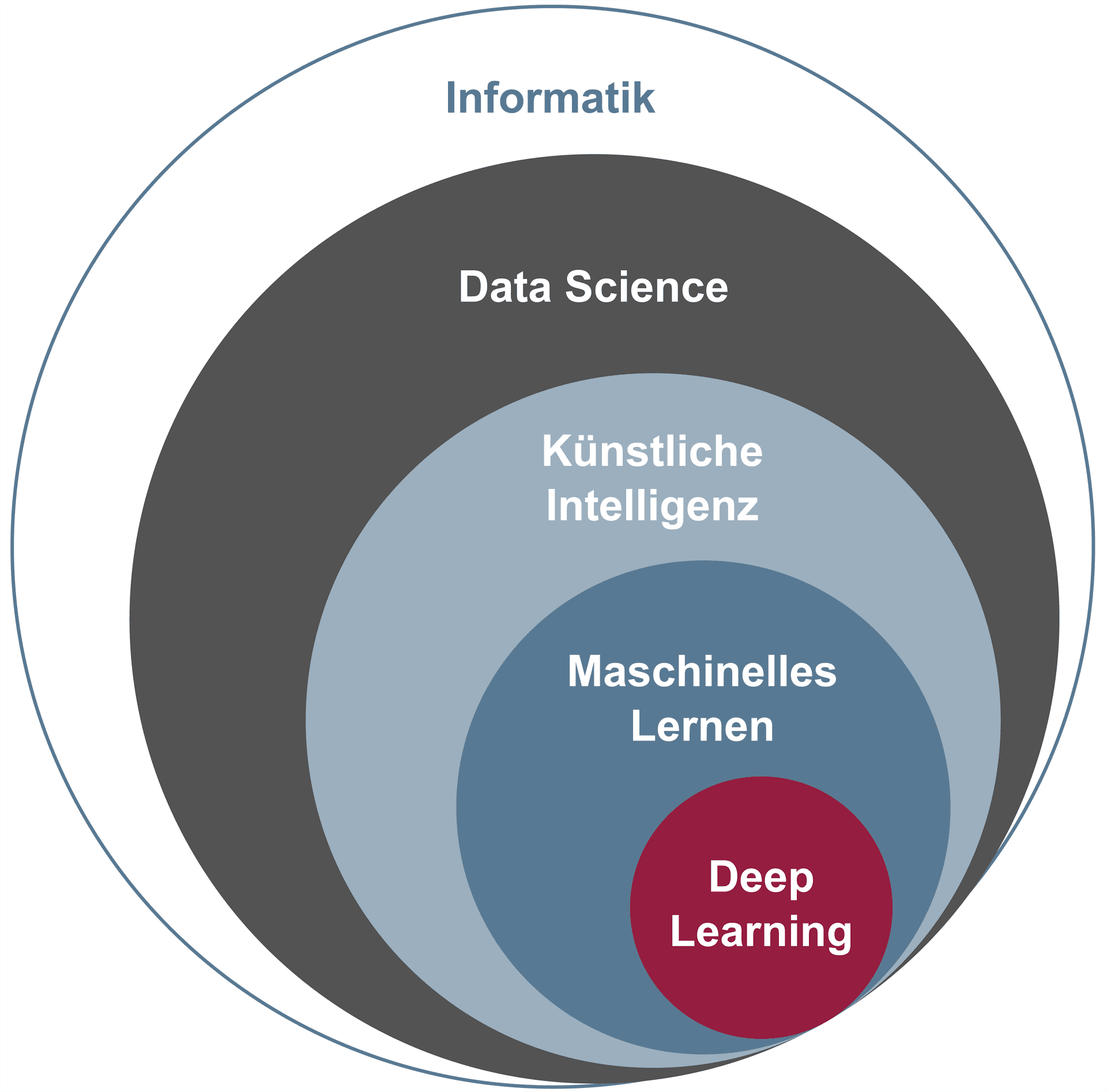
Künstliche Intelligenz kann wie folgt eingeordnet werden:
Data Science
Die Wissenschaft „Data Science“, ein Fachgebiet der Informatik, beschäftigt sich mit der Extraktion von Wissen aus den Informationen in Daten. Da es immer mehr Daten mit Informationen gibt, kann auch immer mehr Wissen aus den Informationen der Daten abgeleitet werden, insbesondere auch im Bereich der Cyber-Sicherheit.
Künstliche Intelligenz
Dabei setzt „Künstliche Intelligenz“ intelligentes Verhalten in Algorithmen um, mit der Zielsetzung, automatisiert „menschenähnliche Intelligenz“ so gut wie möglich nachzubilden. Bei künstlichen Intelligenzen kann zwischen schwacher und starker Künstliche Intelligenz (KI) unterschieden werden. Eine starke KI soll eine Intelligenz schaffen, die dem Menschen gleicht, kommt oder sogar übertrifft, während die schwache KI sich in der Regel mit konkreten Anwendungsproblemen des menschlichen Denkens beschäftigt. Singularität ist die Begrifflichkeit, die das Erreichen der starken Künstlichen Intelligenz beschreibt. Singularität bedeutet, dass sich die „KI-Maschine“ selbstständig verbessert und intelligenter als Menschen ist.
Maschinelles Lernen
Maschinelles Lernen (Machine Learning/ML) ist ein Begriff im Bereich der Künstlichen Intelligenz für die „künstliche“ Generierung von Wissen aus den Informationen in Daten mit der Hilfe von IT-Systemen. Mithilfe der Algorithmen des maschinellen Lernens werden mit vorhandenen Datenbeständen Muster und Gesetzmäßigkeiten erkannt und verallgemeinert, um damit neue Problemlösungen umzusetzen. In Lernphasen lernen entsprechende ML-Algorithmen, aus vielen diversen Beispielen simple Muster und Strukturen, hin zu komplexen Merkmalen und Gesetzmäßigkeiten zu erkennen. Daraus entstehende Regeln können auf neue Daten und ähnliche Situationen angewendet werden, in denen die Künstliche Intelligenz (KI) beispielsweise entscheiden muss, ob es sich um einen Angriff oder eine legitime Nutzeraktion handelt. Maschinelles Lernen wird noch effektiver durch Deep Learning.
Deep Learning
Deep Learning ist eine Spezialisierung des maschinellen Lernens und nutzt vorwiegend künstliche neuronale Netze (KNN).
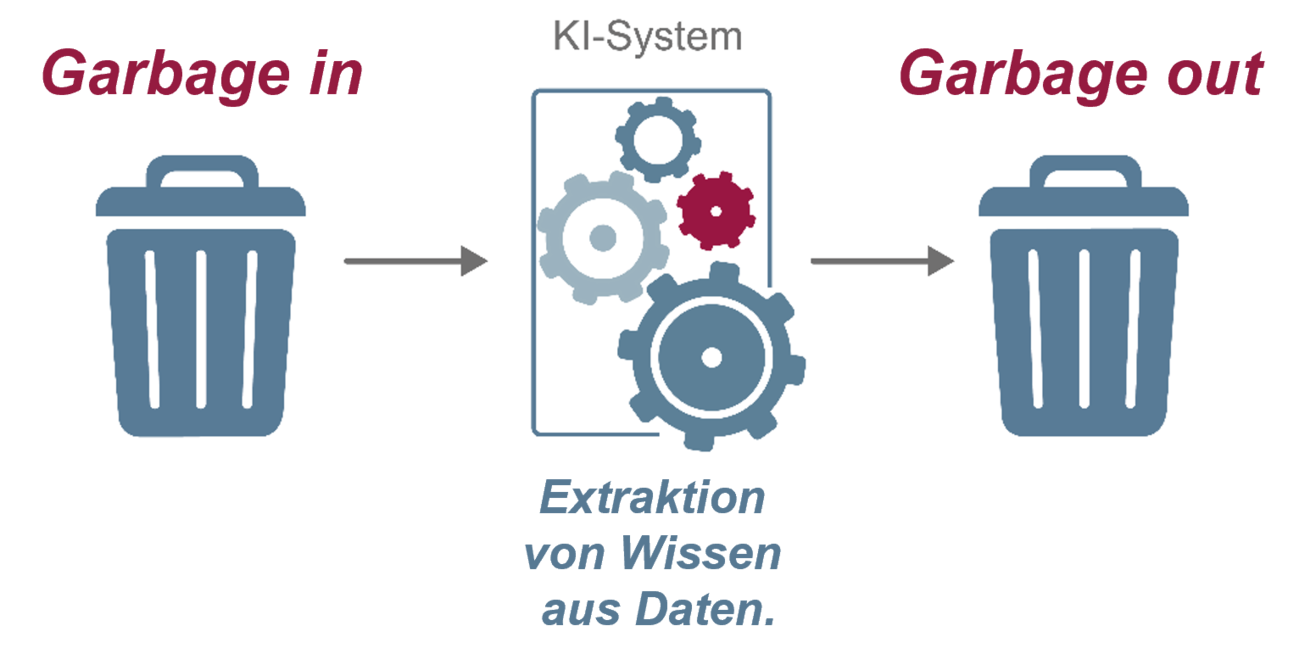
Garbage in, Garbage out bedeutet im Umfeld der KI, dass unabhängig von der Qualität eines KI-Systems die Ergebnisse schlecht sind, wenn die Eingabedaten eine schlechte Qualität haben. Dies leitet sich aus der grundsätzlichen Idee ab: Extraktion von Wissen aus Daten. Wenn in den Daten keine Informationen stehen, kann auch kein Wissen extrahiert werden. Die Ergebnisqualität eines KI-Systems kann normalerweise nicht besser sein als die Qualität der Eingabedaten. Aus diesem Grund müssen die Eingabedaten eine hohe Qualität ausweisen, um ein gutes Ergebnis zu erzielen.
Im Folgenden wird der Faktor Qualität der Eingabedaten diskutiert, um ein gutes Verständnis dafür zu erhalten.
Faktoren der Qualität der Eingabedaten bei KI-Systemen
Wegen der Wichtigkeit der Qualität der Eingabedaten sollte ein Standard der Datenqualität für KI-Systeme etablieret werden. Im Einzelnen sind dabei unter anderem Vollständigkeit, Repräsentativität, Nachvollziehbarkeit, Aktualität und Korrektheit zu berücksichtigen. Außerdem sollte es obligatorisch sein, entsprechende Positionen im Unternehmen zu konstituieren, die für das Modell der Datengewinnung und -nutzung zuständig sowie für die Kontrolle der ordnungsgemäßen Umsetzung verantwortlich sind.
1. Vollständigkeit der Daten Die Grundvoraussetzung für Vollständigkeit ist, dass ein Datensatz alle notwendigen Attribute und Inhalte enthält. Kann die Vollständigkeit der darin inkludierten Daten nicht garantiert werden, entsteht daraus potenziell das Problem von irreführenden Tendenzen, was letztendlich zu falschen oder diskriminierenden Ergebnissen führt. Dieses Phänomen tritt unter anderem bei Predictive Policing-Systemen auf: Wenn beispielsweise die Datenerhebung zu Kriminalitätsdelikten von vorneherein massiv in definierten Stadtvierteln stattfindet und dies im Kontext mit bestimmten Merkmalen wie Herkunft und Alter geschieht, ergibt sich daraus im Laufe der Zeit, dass dort bestimmte Bevölkerungsgruppen stärker überwacht und durch die häufiger durchgeführten Kontrollen letztendlich per se kriminalisiert werden. Der (vermeintliche) Tatbestand kann jedoch unter Umständen lediglich darauf basieren, dass entsprechende Vergleichswerte unter Berücksichtigung der gleichen Merkmale aus anderen Stadtvierteln nicht im adäquaten Maße erhoben wurden. Vollständigkeit bedeutet keinesfalls, wahllos möglichst viele Daten zu erfassen – entscheidend ist die Auswahl.
2. Repräsentativität der Daten Die Repräsentativität zeichnet sich dadurch aus, dass die Daten eine tatsächliche Grundgesamtheit und somit entsprechend die Realität abbilden, die stellvertretend im Sinne der Aufgabenstellung ist. Sind die Daten nicht repräsentativ, hat dies zur Folge, dass daraus ein Bias resultiert. Ein Bias entsteht durch einen Fehler bei der Datenerhebung, der zu einem fehlerhaften Ergebnis führt. Dieses Phänomen tritt beispielsweise im Recruiting von Führungskräften auf, wenn hier größtenteils Daten aus der Vergangenheit berücksichtigt werden und in dieser Zeit überwiegend Männer in Führungspositionen waren. Mit der Konsequenz, dass die KI-basierte Anwendung daraus folgern müsste, dass Männer für diese Positionen qualifizierter seien. Ergebnisse wie diese zeigen, dass durch KI-Systeme nicht zwangsläufig Objektivität erreichbar ist.
3. Nachvollziehbarkeit der Daten Für die Überprüfung der Datenqualität ist es essenziell, dass nachvollzogen werden kann, aus welchen Quellen die verwendeten Daten stammen. Sind die Quellen nicht transparent, das heißt nicht nachvollziehbar, ist es nicht möglich eine notwendige Validierung der Daten vorzunehmen, was sich letztendlich auf deren Qualität negativ auswirken kann. Für eine bestmögliche Bewertung und Messung sowohl der Datenqualität als auch der Qualität der Quellen sowie der Ableitung gezielter Verbesserungsmaßnahmen, müssen im Vorfeld entsprechend Vorgaben definiert werden. Hierfür gilt es, die für den Prozess relevanten Kriterien zu bestimmen, etwa Konsistenz oder Einheitlichkeit. Anhand der gewählten Kriterien ist es dann möglich, die erhobenen Daten bezüglich ihrer konsistenten Qualität zu überprüfen. Hierbei sind noch zwei relevante Aspekte zu bedenken: Zum einen kommen Daten oft aus unterschiedlichen Quellen mit verschiedenen Formaten, die vor dem Einsatz auf ihre Utilität verifiziert werden müssen. Zum anderen ist die Nachvollziehbarkeit – gerade im Produktionsumfeld – auch durch die Förderung von qualitativ hochwertigen und sicheren Sensoren abhängig.
4. Aktualität der Daten Die grundsätzliche Idee beim Maschinellen Lernen oder KI ist die Extraktion von Wissen aus Daten. Aus diesem Grund muss sichergestellt werden, dass die generierten, respektive verwendeten Daten auch die passenden Informationen und Erfahrungen enthalten, um mit den KI-Algorithmen das Problem richtig und vertrauenswürdig zu lösen. Nicht zuletzt aufgrund der Tatsache, dass Menschen sich nicht linear verhalten, können veraltete Daten zu falschen Ergebnissen führen. Aus diesem Grund sollten – in Abhängigkeit von der Anwendung – möglichst die aktuellsten Daten verwendet werden.
5. Korrektheit der Daten Die Daten müssen mit der Realität übereinstimmen und damit für die Anwendung korrekt sein. Die Auswahl der Daten bedingt, dass diese Anforderungen mit einer detaillierten Analyse ermittelt wurden – als Methode kann hier das Mapping gegen Daten, deren Korrektheit bestätigt ist, oder definierte, abgestimmte Plausibilitätsregeln eingesetzt werden. So lässt sich sicherstellen, dass zwischen den – zur Entwicklung oder im Weiteren in der Anwendung – genutzten Daten und der Realität keine Diskrepanz besteht.
Künstliche Intelligenz hat das Ziel, automatisiert „menschenähnliche Intelligenz“ in Algorithmen nachzubilden. Bei künstlicher Intelligenz kann zwischen schwacher und starker künstlicher Intelligenz (KI) unterschieden werden.
Author
Prof. Norbert Pohlmann
Publisher Name
Institut für Internet-Sicherheit – if(is)
Publisher Logo
Künstliche Intelligenz Prof. Dr. Norbert Pohlmann - Cyber-Sicherheitsexperten