Maschinelles Lernen ist die „künstliche“ Generierung von Wissen aus den Informationen in Daten mit der Hilfe von IT-Systemen. Mithilfe der Algorithmen des maschinellen Lernens werden mit vorhandenen Datenbeständen Muster und Gesetzmäßigkeiten erkannt und verallgemeinert, um damit neue Problemlösungen umzusetzen. In Lernphasen lernen entsprechende maschinelles Lernen Algorithmen, aus vielen diversen Beispielen simple Muster und Strukturen, hin zu komplexen Merkmalen und Gesetzmäßigkeiten zu erkennen. Daraus entstehende Regeln können auf neue Daten und ähnliche Situationen angewendet werden, in denen maschinelles Lernen beispielsweise entscheiden muss, ob es sich um einen Angriff oder eine legitime Nutzeraktion handelt.
Prinzip des Maschinellen Lernens
Die Algorithmen des maschinellen Lernens haben als Input Eingangsdaten mit Informationen, berechnen mit einem Algorithmus nach einem vorgegebenen Verfahren und liefern als Output die Ergebnisse. Die Anwendung entscheidet, wie die Verwendung der Ergebnisse stattfinden soll.
Ergebnisse Ergebnisse aus der Verarbeitung der Eingangsdaten mit den Algorithmen können sein: • Klassifizierung der Eingangsdaten, wie Erkennung von Angriffen • numerische Werte, wie Hinweise zur Verbesserung eines Produkts • binäre Werte, wie eine erfolgreiche biometrischer Authentifizierung
Verwendung Die Anwendung entscheidet, wie die Ergebnisse verwendet werden.
Kategorien und Algorithmen des Maschinellen Lernens
1. Kategorie: Überwachtes Lernen Beim überwachten Lernen wird ein Algorithmus mithilfe von Eingabedaten und Ergebnissen trainiert. Dadurch kann der Algorithmus lernen, ob das Ergebnis mit den Eingabedaten den Erwartungen entspricht. Zum Aufgabenfeld des überwachten Lernens gehört das Regressions- und Klassifizierungsproblem. Mit der Regressionsanalyse ist es möglich, Werte von abhängigen Variablen zu prognostizieren. Aufgaben der Klassifikation befassen sich damit, Daten in verschiedene Klassen mit ähnlichen Ausprägungen einzuteilen.
Ziele des überwachten Lernens sind: • Regression: Vorhersagen von numerischen Werten • Klassifizierung: Einteilung von Eingabedaten in Klassen
Maschinelles Lernen Algorithmen aus dem Bereich des überwachten Lernens sind zum Beispiel: • Support-Vector-Machine (SVM) • k-Nearest-Neighbor (kNN)
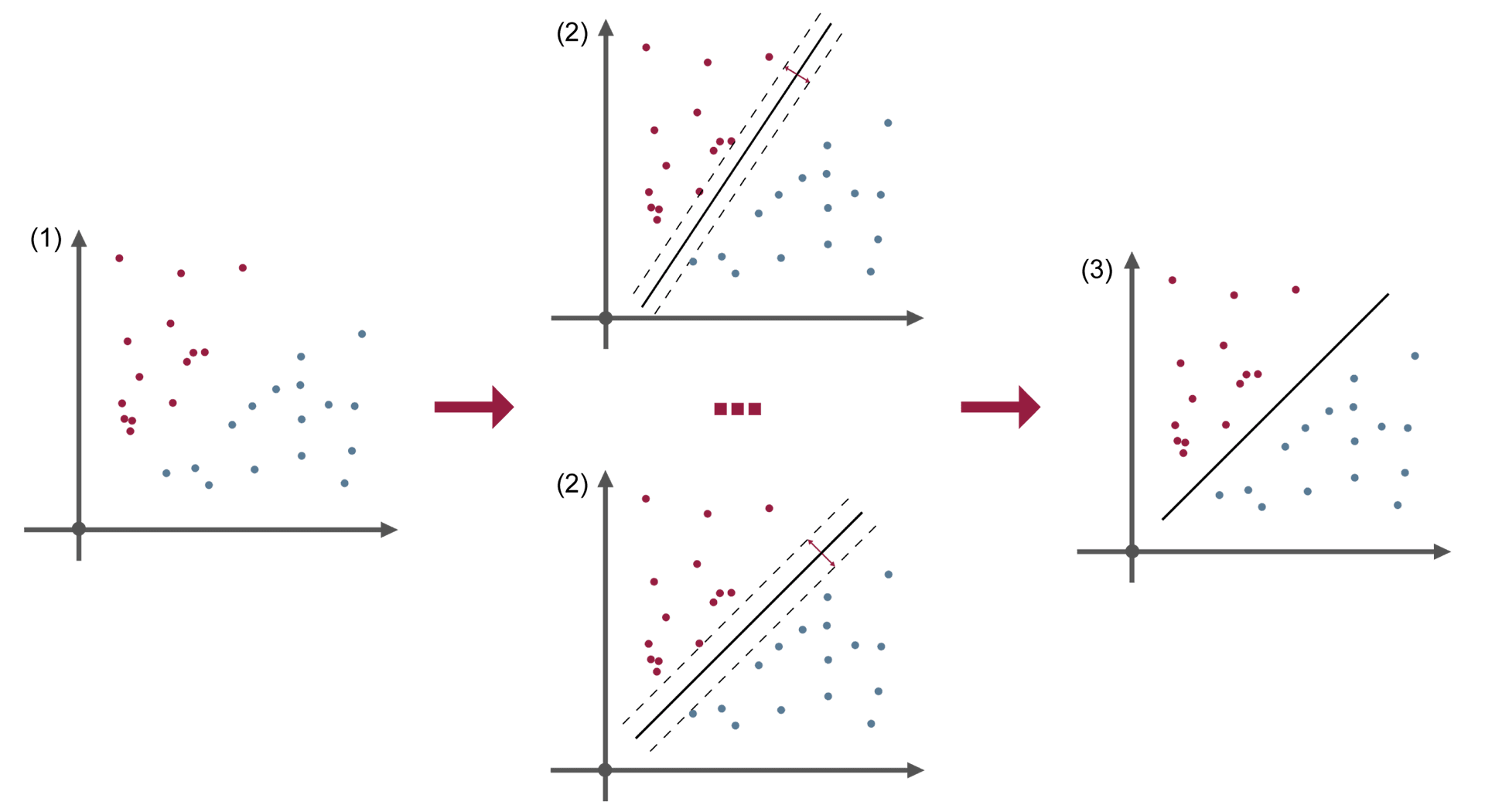
Support-Vector-Machine (SVM)
Eine Support-Vector-Machine ist ein mathematisches Verfahren zur Klassifizierung von Eingabedaten (Objekte). Eine SVM arbeitet mit Trainingsdaten, für die bereits definiert ist, welcher Klasse sie zugehören. Jedes Eingabedatum wird dabei durch einen Vektor in einem n-dimensionalen Vektorraum repräsentiert. Für diesen Vektorraum versucht die SVM, eine optimale Hyperebenen zu berechnen, um damit die Daten in zwei Klassen zu unterteilen. Im Bild ist exemplarisch dargestellt, wie in einem zweidimensionalen Raum nach einer optimalen Hyperebene zu den gegebenen Eingabedaten gesucht wird. In einem n-dimensionalen Raum hat die Hyperebene die Dimension n − 1. Aus diesem Grund ist jede der betrachteten Hyperebenen in dem dargestellten Beispiel eine Linie. Eine Hyperebene ist optimal, wenn der Abstand zu den sogenannten „Support-Vectors“ am höchsten ist. Ein „Support-Vector“ ist der nächste Vektor einer Klasse zu der betrachteten Hyperebene. In dem dargestellten Beispiel sind es jeweils die nächsten Punkte einer Klasse (rot oder blau) zu der betrachteten Linie.
Eingabedaten: (1) • Klassifizierte Objekte (Trainingsdaten, für die bereits definiert ist, welcher Klasse sie zugehören) • Abstandsmaß der Objekte untereinander (durch Beschreibung als Vektor)
ML-Algorithmus: (2) • Ermitteln von Geraden zur Trennung der klassifizierten Objekte • Bewertung durch Abstand zu den Punkten • Wahl der Geraden mit maximalem Abstand zu beiden Klassen
Ergebnis: (3) • Gerade als Modell zur Klassifizierung Danach klassifiziert das Modell mithilfe der Lage der Punkte der Eingabewerte in eine Klasse.
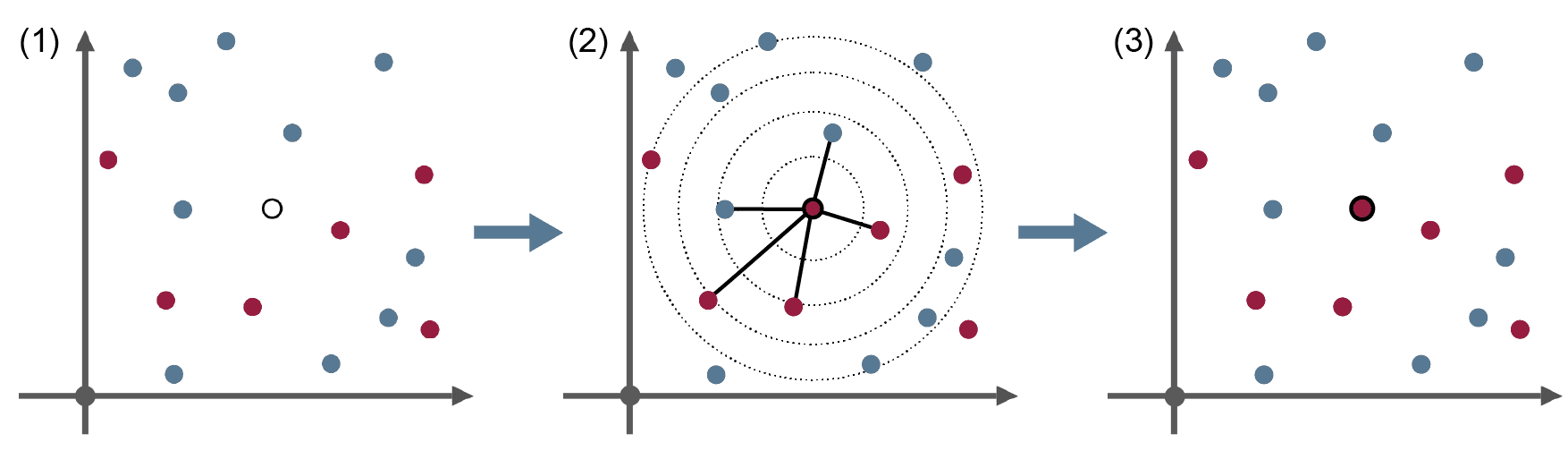
k-Nearest-Neighbor (kNN)
Der k-Nearest-Neighbor-Algorithmus ist ein Klassifikationsverfahren, bei dem eine Klassenzuordnung auf Basis seiner k nächsten Nachbarn durchgeführt wird. Auch bei diesem Klassifikationsverfahren müssen bereits klassifizierte Objekte vorhanden sein. Die Klassifikation eines neuen Objektes erfolgt im einfachsten Fall durch Mehrheitsentscheidung. Für die Mehrheitsentscheidung werden die k nächsten bereits klassifizierten Objekte herangezogen. Als Maß für den Abstand der Objekte zueinander kann zum Beispiel die euklidische Distanz verwendet werden.
Eingabedaten: (1) • bereits klassifizierte Objekte • Anzahl der zu betrachtenden Nachbarobjekte k • unklassifiziertes Objekt, das klassifiziert werden soll
ML-Algorithmus: (2) • Berechnung der Distanz zu allen anderen Objekten • Betrachtung der k nächsten Nachbarobjekte • Zuordnung zur am häufigsten vorkommenden Klasse
Ergebnis: (3) • Klassifizierung des neuen Objekts durch Mehrheitsentscheidung
2. Kategorie: Unüberwachtes Lernen Beim unüberwachten Lernen werden Muster und Gesetzmäßigkeiten in unklassifizierten Objekten gesucht. Die Stärke im unüberwachten Ansatz liegt darin, nach Mustern auch in unklassifizierten Daten zu suchen, um sie nach vorheriger Aufbereitung besser beschreiben zu können. Mittels Clustering werden ähnliche Datengruppen miteinander in Verbindung gesetzt. Die Erwartungshaltung an diesen Ansatz liegt unter anderem darin, Dinge zu erkennen, die vorher anderweitig nicht sichtbar waren. Sie ist im Weiteren auch gut geeignet, um unüberschaubare Datenmengen auf die wichtigsten Eigenschaften sowie Kriterien zu reduzieren. Da der Algorithmus selbstständig lernt, werden klassische Fehler in diesem Sinne nicht produziert. Dies kann jedoch zu einem anderen Problem führen: Lernt der Algorithmus auch in die gewünschte Richtung? Zur Überprüfung des unüberwachten Lernens müssen folglich alle relevanten Gegebenheiten miteinander abgeglichen werden, um so Korrelationen zu finden. Clustering setzt ähnliche Datengruppen miteinander in Verbindung.
Maschinelles Lernen Algorithmen aus dem Bereich des unüberwachten Lernens sind zum Beispiel: • k-Means-Algorithmus • hierarchische Clustering-Verfahren
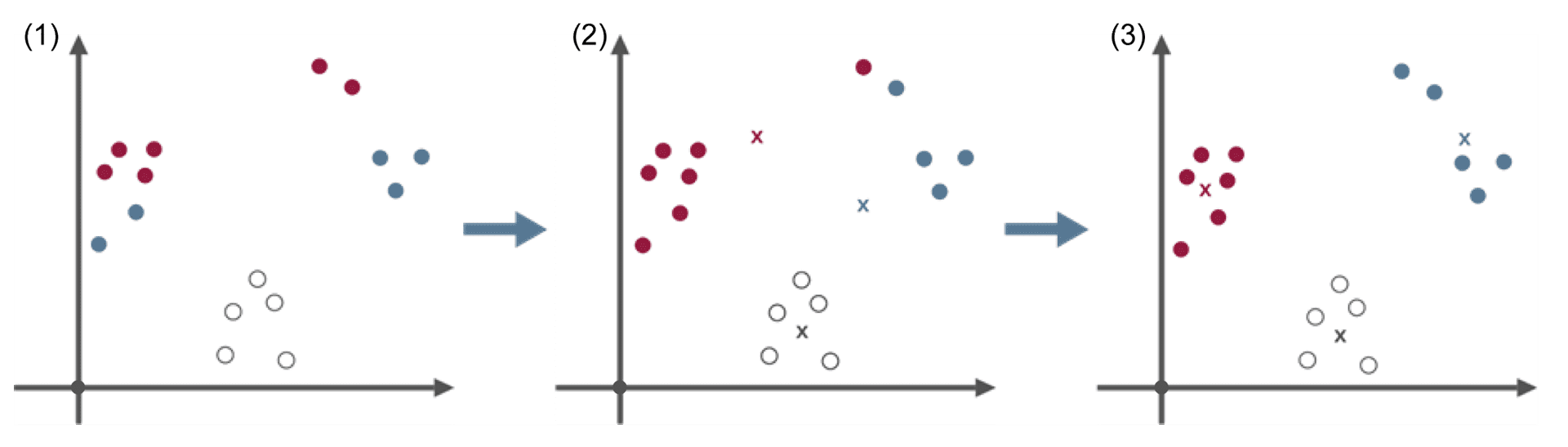
k-Means-Algorithmus
Der k-Means-Algorithmus ist ein Verfahren zur Clusteranalyse. Mit vorhandenen Eingangsdaten werden zufällig aus den gebildeten Mittelwerten für jedes Cluster ein Zentrum (Zentroid) ausgewählt. Die Elemente werden initial (zum Beispiel zufällig) zu den Clustern zugeordnet. Im nächsten Schritt werden die Abstände der einzelnen Punkte zum Beispiel mithilfe der euklidischen Distanz zu den Zentroiden neu berechnet. Dann werden die Elemente zu den am nächsten befindlichen Zentroid und seinem Cluster zugeordnet. Im nächsten Schritt werden die Zentroide erneut berechnet und die Elemente dementsprechend zugeordnet. Diese Schritte wiederholen sich iterativ so lange, bis kein Punkt mehr zu einem anderen Cluster zugeordnet werden kann. Der k-Means-Algorithmus ist einfach umzusetzen. Er besteht im Prinzip nur aus Abstandsberechnungen und Neuzuordnungen und kommt iterativ zu einem stabilen und effektiven Cluster. Die Anzahl der gewünschten Cluster müssen als Eingabewert (k) bestimmt werden.
Eingabedaten (1) • beliebige Objekte • Abstandsmaß • Anzahl k Cluster • initiale Zuordnung der Elemente zu Clustern (zum Beispiel zufällig)
ML-Algorithmus (2) • Berechnung der Schwerpunkte (Zentroide) • Zuordnung der Elemente zu Cluster mit dem nächsten Zentroid • Neuberechnung der Zentroide und erneute Zuordnung
Ergebnis (3) • Einteilung der Objekte in k Cluster
Hierarchische Clustering-Verfahren
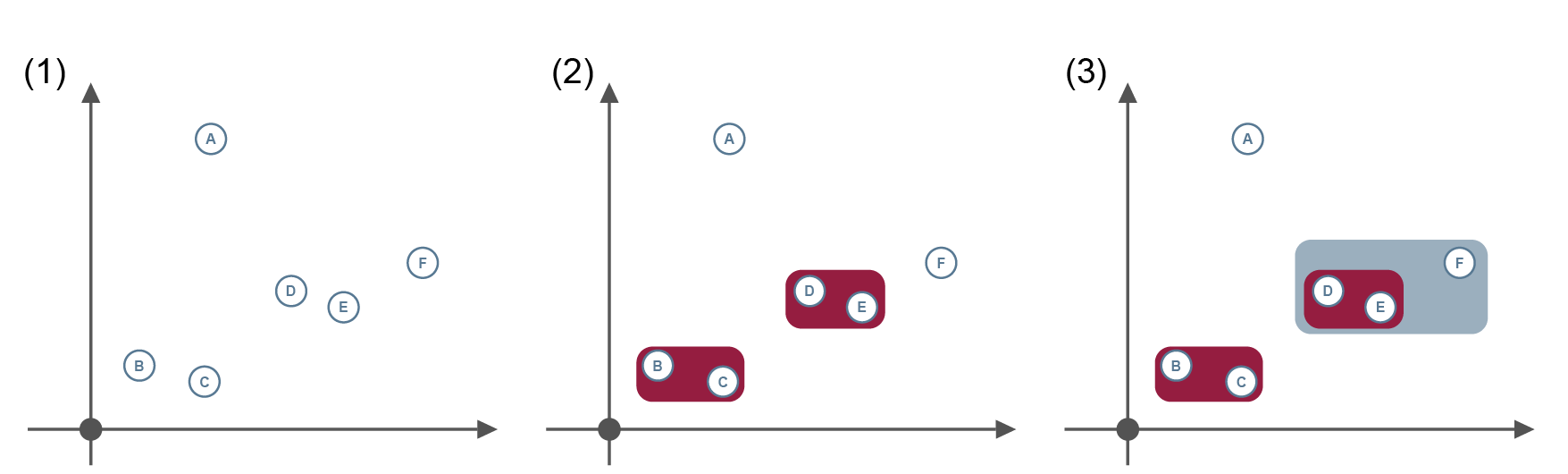
Bei hierarchischen Cluster-Verfahren entstehen geschachtelte Cluster, die wiederum aus Clustern entstehen. Hierbei werden zu Anfang viele kleine Cluster gebildet, die im weiteren Verlauf zu größeren Clustern zusammengeführt werden. Das Ergebnis wird in einem Dendrogramm dargestellt. Jedes Objekt der Eingabedaten ist zu Beginn ein eigenes Cluster. Durch das gewählte Ähnlichkeitsmaß werden ähnliche Cluster zu einem größeren Cluster zusammengeführt. Die zusammengeführten Cluster werden wiederum als Eingabedaten verwendet und weiter zusammengeführt. So entsteht nach jeder Iteration eine hierarchische Struktur.
ML-Algorithmus (1) bis (5) • jeder Datenpunkt ist ein eigenes Cluster • ähnliche Cluster werden zuerst zusammengeführt • entstandene Cluster werden erneut als Eingabedaten verwendet • iteratives Zusammenführen der Cluster induziert eine hierarchische Struktur
Ergebnis (6) • hierarchische Beziehungen zueinander in Form eines Binärbaums (Dendrogramm)
Wo kommt maschinelles Lernen im Anwendungsszenario Cyber-Sicherheit zum Einsatz?
Ausgewählte Anwendungsszenarien von Maschinellen Lernen (schwache KI) und Cyber-Sicherheit, um die Anwendungsvielfalt zu demonstrieren.
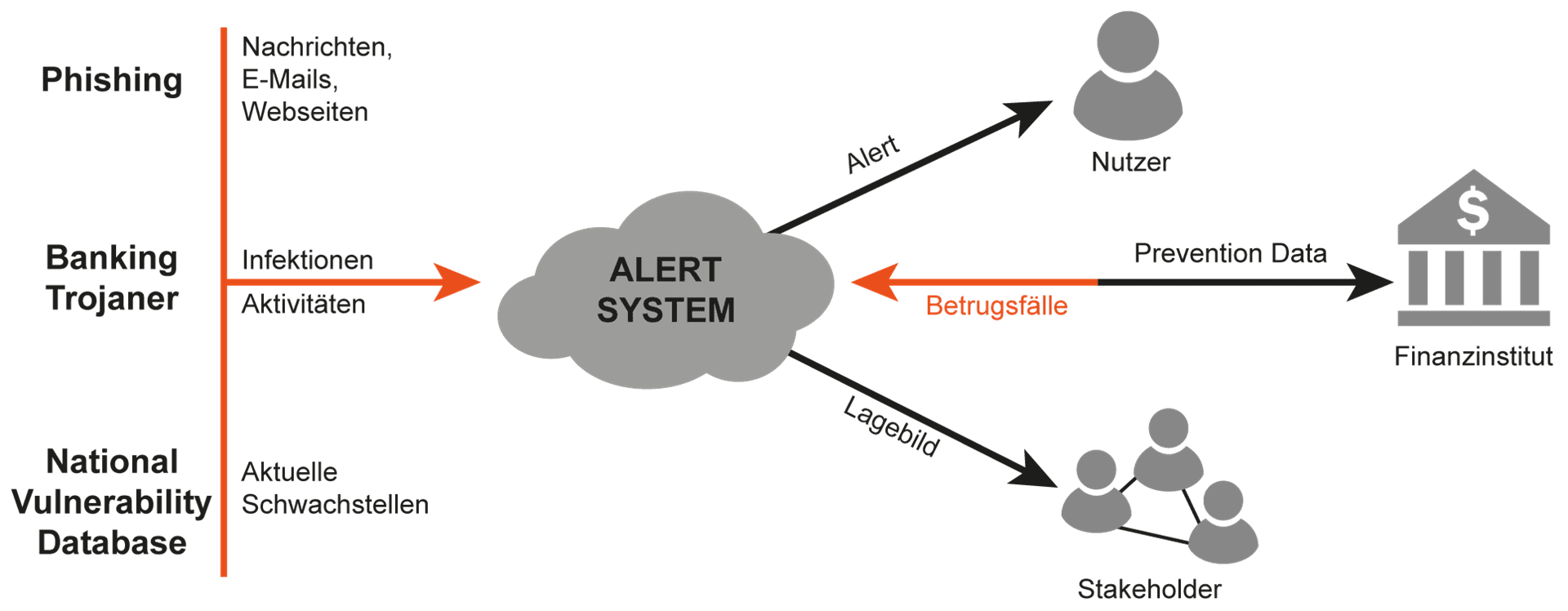
1.) Betrugsschutz im Online-Banking Im Bereich des Online-Bankings kann zum Beispiel mithilfe von maschinellen Lernen (schwache KI) ermittelt werden, ob eine erhöhte Bedrohungslage herrscht. Dazu werden verschiedene Datenquellen herangezogen und beispielsweise ermittelt, wie viele Banking-Trojaner aktuell aktiv sind. Zudem wird geschaut, ob es aktuell bekannte Software-Schwachstellen im Umfeld von Online-Banking gibt, die für einen Angriff auf Bankkunden verwendet werden könnten oder ob derzeit vermehrt versucht wird, mit Phishing-Mails Zugangsdaten zu Online-Konten abzugreifen. Diese und andere Indikatoren, wie identifizierte Betrugs- oder Betrugsversuchsfälle der Bank, können dann verwendet werden, um mit verschiedensten Algorithmen aus dem Bereich des maschinellen Lernens ein Bedrohungslagebild zu erstellen. Sie helfen auch dabei, den Bankkunden bei hoher Bedrohung zu warnen und entsprechend aufzuklären, um die Schäden zu verhindern.
2.) Erkennen von Angriffen über das Internet und Kommunikationslagebild Durch die Analyse der Kommunikationsdaten können mit Hilfe von Maschinellen Lernen (schwache KI), Angriffe über das Internet erkannt werden. Dadurch können die Kommunikationsmöglichkeiten entsprechend reduziert werden, um den Angriff abzuwehren. Die Reduzierung kann sich zum Beispiel auf einen bestimmten Port oder die ganze Internet-Kommunikation beziehen. Ob ein IT-Sicherheitsexperte bei der Entscheidung eingebunden wird oder das Cyber-Sicherheitssystem dies automatisiert durchführt, ist ein wichtiger Aspekt für die Effektivität und Kosten des Systems. Die Ergebnisse können dann in ein Security Information and Event Management (SIEM)-System einfließen und zum besseren Management bei Vorfällen führen. Zusätzlich kann auch ein Kommunikationslagebild erstellt werden, um Angriffe, Bedrohungen und Schwachstellen eines Netzwerks auszuwerten und Handlungsempfehlungen zu geben. Siehe auch: Cyber-Sicherheits-Frühwarn- und Lagebildsystem
3.) Authentifikationsverfahren Passive, kontinuierliche Authentifizierung ist besonders bei der zunehmenden Verbreitung mobiler Endgeräte ein Zukunftsfeld für KI-Algorithmen / Maschinelles Lernen. Sensordaten aus Beschleunigungsmessgeräten oder Gyroskopen können während der Nutzung des Gerätes erhoben und ausgewertet werden. Die KI kann folglich unberechtigte Nutzer von der Gerätenutzung ausschließen. Solche Authentifizierungsverfahren sind ein weiterer Schritt zur Usability von robusten und sicheren Cyber-Sicherheitsmechanismen. Diese sind außerdem inklusiv, da sie keine zusätzliche Nutzerinteraktion erfordern und auch von Nutzern mit (bspw. kognitive) Einschränkungen genutzt werden können. Neben der Analyse von Sensordaten ist auch eine verbesserte Authentifizierung anhand von Bild- oder Spracherkennung möglich, da die Hardware zum Aufnehmen in den Endgeräten vorhanden und die Algorithmen zur Auswertung besser geworden sind.
4.) Malware-Erkennung Die konventionelle Malware-Erkennung basiert zumeist auf signaturorientierten Detektoren, die bei einer Überprüfung die Signaturen von Dateien und Programmen mit bekannten Signaturen von Malware vergleicht. Wird Malware jedoch nur minimal verändert, kann die Signatur nicht mehr zur Erkennung genutzt werden. Die heutige Malware verändert sich daher dynamisch. Dies hat zur Folge, dass immer neuere Varianten erscheinen und die Analyse und Aktualisierungen der Signatur-Datenbanken kaum noch effizient zu bewältigen ist. KI-basierte Detektoren können genutzt werden, um in Echtzeit verdächtige Aktivitäten zu erkennen. Anomalie-Erkennung oder Predictive Malware Analysis sind Verfahren, die durch den Einsatz von KI deutlich verbessert werden können.
5.) IT-Forensik Im Bereich der IT-Forensik werden KI-Systeme ebenfalls ein relevanter Faktor. Durch die vermehrte Verlagerung von Lebensbereichen in die digitale Welt werden auch zunehmend Straftaten im digitalen Raum begangen, deren Spuren in den gewaltigen Datenmengen der alltäglichen Nutzung gefunden werden müssen. Dabei stoßen klassische Analysewerkzeuge immer schneller an ihre Grenzen, da IT-Systeme prinzipiell heterogener Natur sind. Verschiedenste IT-Geräte mit unterschiedlichen Betriebssystemen, Installationen und Konfigurationen können unzählige Fragmente aufweisen, die im Kontext von Ermittlungen vielfältige Relevanz besitzen. KI-Anwendungen können hier beispielsweise dabei helfen zu entscheiden, ob bestimmte „Adressen“ von einer verdächtigten Person kontaktiert wurden, oder ob es sich um Fragmente handelt, die von Software-Entwicklern standardmäßig in ihr Programm eingebunden wurden – wie es unter anderem bei Support-Adressen häufig der Fall ist.
Maschinelles Lernen (schwache KI) im Bereich Cyber-Sicherheit wird helfen, Angriffe besser zu identifizieren, die wenigen Cyber-Sicherheitsexperten zu unterstützen und die Wirkung von Cyber-Sicherheitslösungen zu erhöhen. Außerdem wird IT-Sicherheit benötigt, um den Schutz von Künstlicher Intelligenz und deren Ergebnissen zu gewährleisten.
Maschinelles Lernen ist die „künstliche“ Generierung von Wissen aus den Informationen in Daten mit der Hilfe von IT-Systemen. Mithilfe der Algorithmen des maschinellen Lernens werden mit vorhandenen Datenbeständen Muster und Gesetzmäßigkeiten erkannt und verallgemeinert, um damit neue Problemlösungen umzusetzen.
Author
Prof. Norbert Pohlmann
Publisher Name
Institut für Internet-Sicherheit – if(is)
Publisher Logo
Maschinelles Lernen Prof. Dr. Norbert Pohlmann - Cyber-Sicherheitsexperten